
This article offers you 15 top Java multithreading questions that are sure to help you ace your next interview!

Enroll today for Java training in Electronic City Bangalore and get your Java certification, and start your
a career at the best multinational company.
Before we begin the important Interview questions for core java, let’s understand what Java Multithreading is all about.
What is Java Multithreading?
Multithreading is a core Java feature that allows multiple threads to run at the same time. Threads are essentially subprocesses, usually blocks of code that performs specific functions. Java multithreaded interview questions are often asked during job interviews for software developers, such as Interviews with front-end, back-end, and full-stack developers. If Java is the programming language of choice, these Java multithreaded interview questions provide good ideas about what to expect during the interview.
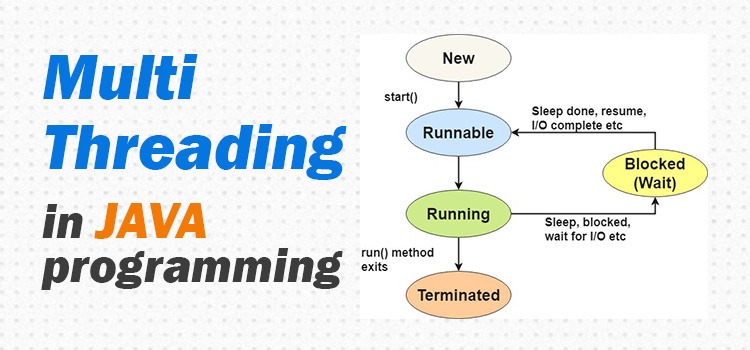
Multithreading and synchronization are considered typical chapters in Java programming. Game development companies mainly ask questions about multithreaded interviews. Below is a list of frequently asked questions about Java multithreading and concurrency interviews.
1. Difference between semaphore and mutex?
Semaphore:
- A semaphore restricts the number of simultaneous users of a shared resource up to a maximum number. Threads can request access to the resource (decrementing the semaphore) and can signal that they have finished using the resource (incrementing the semaphore).
- Counting Semaphore in java maintains a specified number of passes or permits
- In order to access the shared resource, the current thread must acquire a permit
- If the permit is already exhausted by another thread then it can wait until a permit is available due to the release of the permit from a different thread
- java.util.The Semaphore class represents a Counting semaphore which is initialized with the number of permits.
- Semaphore provides two main methods acquire() and release() for getting permits and releasing permits.
- A Counting semaphore with one permit is known as a binary semaphore because it has only two state permits available or permits unavailable.
- They are able to make threads wait when the counter value is zero i.e. they act as Locks with counter functionality.
- When a thread has finished the use of the shared resource, it must release the semaphore so that the other threads can access the shared resource. That operation increases the internal counter of the semaphore.
Example Program for Semaphore:
| import java.util.concurrent.Semaphore; public class SemaphoreTest { Semaphore binary = new Semaphore(1); public static void main(String args[]) { final SemaphoreTest test = new SemaphoreTest(); new Thread(){ @Override public void run(){ test.mutualExclusion(); } }.start(); new Thread(){ @Override public void run(){ test.mutualExclusion(); } }.start(); } private void mutualExclusion() { try { binary.acquire(); //mutual exclusive region System.out.println(Thread.currentThread().getName() + ” inside the mutual exclusive region”); Thread.sleep(1000); } catch (InterruptedException i.e.) { ie.printStackTrace(); } finally { binary.release(); System.out.println(Thread.currentThread().getName() + ” outside of the mutual exclusive region”); } } } |
| Output: Thread-0 inside the mutual exclusive region Thread-0 outside of the mutual exclusive region Thread-1 inside the mutual exclusive region Thread-1 outside of the mutual exclusive region |
Mutex:
- The word mutex is shorthand for a primitive object that provides MUTual EXclusion between threads.
- A mutual exclusion (mutex) is used cooperatively between threads to ensure that only one of the cooperating threads is allowed to access the data or run a certain application code at a time.
- Any thread that successfully locks the mutex is the owner until it unlocks the mutex.
- Any thread that attempts to lock the mutex waits until the owner unlocks the mutex.
- When the owner unlocks the mutex, control is returned to one waiting thread with that thread becoming the owner of the mutex.
- There can be only one owner of a mutex.
Example Program for Mutex:
| import com.sun.corba.se.impl.orbutil.concurrent.Mutex; public class MutexTest { Mutex binary = new Mutex(); public static void main(String args[]) { final MutexTest test = new MutexTest(); new Thread(){ @Override public void run(){ test.mutualExclusion(); } }.start(); new Thread(){ @Override public void run(){ test.mutualExclusion(); } }.start(); } private void mutualExclusion() { try { binary.acquire(); //mutual exclusive region System.out.println(Thread.currentThread().getName() + ” inside the mutual exclusive region”); Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { binary.release(); System.out.println(Thread.currentThread().getName() + ” outside of the mutual exclusive region”); } } } |
| Output: Thread-0 inside the mutual exclusive region Thread-0 outside of the mutual exclusive region Thread-1 inside the mutual exclusive region Thread-1 outside of the mutual exclusive region |
2. Print odd and even numbers in sequence using two threads in java?
| public class EvenOddThreadExample { public static void main(String[] args) { SharedPrinter sp = new SharedPrinter(); Thread t1 = new Thread(new OddNumProducer(sp, 10)); Thread t2 = new Thread(new EvenNumProducer(sp,10)); t1.start(); t2.start(); } } class SharedPrinter { boolean evenFlag = false; public void printOddNumber(int number) { synchronized(this) { while (evenFlag) { try { wait(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } System.out.println(“Odd Number : ” + number); evenFlag = true; notify(); } } public void printEvenNumber(int number) { synchronized(this) { while (!evenFlag) { try { wait(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } System.out.println(“Even Number : ” + number); evenFlag = false; notify(); } } } class OddNumProducer implements Runnable { SharedPrinter sp; int number; public OddNumProducer(SharedPrinter s, int num) { this.sp = s; this.number = num; } @Override public void run () { for (int i=1; i <= number; i = i+2) { sp.printOddNumber(i); } } } class EvenNumProducer implements Runnable { SharedPrinter sp; int number; public EvenNumProducer(SharedPrinter s, int num) { this.sp = s; this.number = num; } @Override public void run() { for (int i = 2; i <= number; i=i+2) { sp.printEvenNumber(i); } } } |
3. Explain Fork Join Framework?
- Basically, the Fork-Join breaks the task at hand into mini-tasks until the mini-task is simple enough that it can be solved without further breakups.
- It’s like a divide-and-conquer algorithm. One important concept to note in this framework is that ideally, no worker thread is idle.
- They implement a work-stealing algorithm in that idle workers steal the work from those workers who are busy.
Core Classes used in Fork/Join Framework
The core classes supporting the Fork-Join mechanism are ForkJoinPool and ForkJoinTask.
ForkJoinPool
- The ForkJoinPool is basically a specialized implementation of ExecutorService implementing the work-stealing algorithm we talked about above. We create an instance of ForkJoinPool by providing the target parallelism level i.e. the number of processors as shown below:
| ForkJoinPool pool = new ForkJoinPool(numberOfProcessors); Where numberOfProcessors = Runtime.getRunTime().availableProcessors(); |
- If you use a no-argument constructor, by default, it creates a pool of size that equals the number of available processors obtained using the above technique.
- Although you specify any initial pool size, the pool adjusts its size dynamically in an attempt to maintain enough active threads at any given point in time. Another important difference compared to other ExecutorService’s is that this pool need not be explicitly shut down upon program exit because all its threads are in daemon mode.
- There are three different ways of submitting a task to the ForkJoinPool.
- execute() method //Desired asynchronous execution; call its fork method to split the work between multiple threads.
- invoke() method: //Await to obtain the result; call the invoke method on the pool.
- submit() method: //Returns a Future object that you can use for checking the status and obtaining the result on its completion.
ForkJoinTask
- This is an abstract class for creating tasks that run within a ForkJoinPool. The RecursiveAction and RecursiveTask are the only two direct, known subclasses of ForkJoinTask. The only difference between these two classes is that the RecursiveAction does not return a value while RecursiveTask does have a return value and returns an object of the specified type.
- In both cases, you would need to implement the compute method in your subclass that performs the main computation desired by the task.
- The ForkJoinTask class provides several methods for checking the execution status of a task. The isDone() method returns true if a task completes in any way. The isCompletedNormally() method returns true if a task completes without cancellation or encountering an exception, and isCancelled() returns true if the task was canceled. Lastly, isCompletedabnormally() returns true if the task was either canceled or encountered an exception.
Example
- In this example, you will learn how to use the asynchronous methods provided by the ForkJoinPool and ForkJoinTask classes for the management of tasks.
- You are going to implement a program that will search for files with a determined extension inside a folder and its subfolders.
- The ForkJoinTask class you’re going to implement will process the content of a folder. For each subfolder inside that folder, it will send a new task to the ForkJoinPool class in an asynchronous way. For each file inside that folder, the task will check the extension of the file and add it to the result list if it proceeds.
| FolderProcessor.java package forkJoinDemoAsyncExample; import java.io.File; import java.util.ArrayList; import java.util.List; import java.util.concurrent.RecursiveTask; public class FolderProcessor extends RecursiveTask<List<String>> { private static final long serialVersionUID = 1L; //This attribute will store the full path of the folder this task is going to process. private final String path; //This attribute will store the name of the extension of the files this task is going to look for. private final String extension; //Implement the constructor of the class to initialize its attributes public FolderProcessor(String path, String extension) { this.path = path; this.extension = extension; } //Implement the compute() method. As you parameterized the RecursiveTask class with the List<String> type, this method has to return an object of that type. @Override protected List<String> compute() { //List to store the names of the files stored in the folder. List<String> list = new ArrayList<String>(); //FolderProcessor tasks to store the subtasks that are going to process the subfolders stored in the folder List<FolderProcessor> tasks = new ArrayList<FolderProcessor>(); //Get the content of the folder. File file = new File(path); File content[] = file.listFiles(); //For each element in the folder, if there is a subfolder, create a new FolderProcessor object //and execute it asynchronously using the fork() method. if (content != null) { for (int i = 0; i < content.length; i++) { if (content[i].isDirectory()) { FolderProcessor task = new FolderProcessor(content[i].getAbsolutePath(), extension); task.fork(); tasks.add(task); } //Otherwise, compare the extension of the file with the extension you are looking for using the checkFile() method //and, if they are equal, store the full path of the file in the list of strings declared earlier. else { if (checkFile(content[i].getName())) { list.add(content[i].getAbsolutePath()); } } } } //If the list of the FolderProcessor subtasks has more than 50 elements, rite a message to the console to indicate this circumstance. if (tasks.size() > 50) { System.out.printf(“%s: %d tasks ran.\n”, file.getAbsolutePath(), tasks.size()); } //add to the list of files the results returned by the subtasks launched by this task. addResultsFromTasks(list, tasks); //Return the list of strings return list; } //For each task stored in the list of tasks, call the join() method that will wait for its finalization and then will return the result of the task. //Add that result to the list of strings using the addAll() method. private void addResultsFromTasks(List<String> list, List<FolderProcessor> tasks) { for (FolderProcessor item : tasks) { list.addAll(item.join()); } } //This method compares if the name of a file passed as a parameter ends with the extension you are looking for. private boolean checkFile(String name) { return name.endsWith(extension); } } |
| Main.java package forkJoinDemoAsyncExample; import java.util.List; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.TimeUnit; public class Main { public static void main(String[] args) { //Create ForkJoinPool using the default constructor. ForkJoinPool pool = new ForkJoinPool(); //Create three FolderProcessor tasks. Initialize each one with a different folder path. FolderProcessor system = new FolderProcessor(“C:\\Windows”, “log”); FolderProcessor apps = new FolderProcessor(“C:\\Program Files”, “log”); FolderProcessor documents = new FolderProcessor(“C:\\Documents And Settings”, “log”); //Execute the three tasks in the pool using the execute() method. pool.execute(system); pool.execute(apps); pool.execute(documents); //Write to the console information about the status of the pool every second //until the three tasks have finished their execution. do { System.out.printf(“******************************************\n”); System.out.printf(“Main: Parallelism: %d\n”, pool.getParallelism()); System.out.printf(“Main: Active Threads: %d\n”, pool.getActiveThreadCount()); System.out.printf(“Main: Task Count: %d\n”, pool.getQueuedTaskCount()); System.out.printf(“Main: Steal Count: %d\n”, pool.getStealCount()); System.out.printf(“******************************************\n”); try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } while ((!system.isDone()) || (!apps.isDone()) || (!documents.isDone())); //Shut down ForkJoinPool using the shutdown() method. pool.shutdown(); //Write the number of results generated by each task to the console. List<String> results; results = system.join(); System.out.printf(“System: %d files found.\n”, results.size()); results = apps.join(); System.out.printf(“Apps: %d files found.\n”, results.size()); results = documents.join(); System.out.printf(“Documents: %d files found.\n”, results.size()); } } |
| The output of above program will look like this: Main: Parallelism: 2 Main: Active Threads: 3 Main: Task Count: 1403 Main: Steal Count: 5551 ****************************************** ****************************************** Main: Parallelism: 2 Main: Active Threads: 3 Main: Task Count: 586 Main: Steal Count: 5551 ****************************************** System: 337 files found. Apps: 10 files found. Documents: 0 files found. |
How does it work?
- In the FolderProcessor class, Each task processes the content of a folder. As you know, this content has the following two kinds of elements:
- Files
- Other folders
- If the task finds a folder, it creates another Task object to process that folder and sends it to the pool using the fork() method. This method sends the task to the pool that will execute it if it has a free worker thread or it can create a new one. The method returns immediately, so the task can continue processing the content of the folder. For every file, a task compares its extension with the one it’s looking for and, if they are equal, adds the name of the file to the list of results.
- Once the task has processed all the content of the assigned folder, it waits for the finalization of all the tasks it sent to the pool using the join() method. This method called in a task waits for the finalization of its execution and returns the value returned by the compute() method. The task groups the results of all the tasks it sent with its own results and returns that list as a return value of the compute() method.
Difference between Fork/Join Framework And ExecutorService
The main difference between the Fork/Join and the Executor frameworks is the work-stealing algorithm. Unlike the Executor framework, when a task is waiting for the finalization of the sub-tasks it has created using the join operation, the thread that is executing that task (called worker thread ) looks for other tasks that have not been executed yet and begins its execution. In this way, the threads take full advantage of their running time, thereby improving the performance of the application.
Existing Implementations in JDK
- There are some generally useful features in Java SE which are already implemented using the fork/join framework.
- One such implementation, introduced in Java SE 8, is used by the java.util.Arrays class for its parallelSort() methods. These methods are similar to sort(), but leverage concurrency via the fork/join framework. Parallel sorting of large arrays is faster than sequential sorting when run on multiprocessor systems.
- Parallelism used in Stream.parallel(). Read more about this parallel stream operation in java 8.
4. Explain the Blocking queue in Java?
- BlockingQueue in Java is added in Java 1.5 along with various other concurrent Utility classes like ConcurrentHashMap, Counting Semaphore, CopyOnWriteArrrayList, etc.
- BlockingQueue is a unique collection type that not only stores elements but also supports flow control by introducing blocking if either BlockingQueue is full or empty. take() method of BlockingQueue will block if Queue is empty and put() method of BlockingQueue will block if Queue is full.
- This property makes BlockingQueue an ideal choice for implementing a Producer consumer design pattern where one thread inserts an element into BlockingQueue and another thread consumes it.

- BlockingQueue in Java doesn’t allow null elements, various implementation of BlockingQueue like ArrayBlockingQueue, LinkedBlockingQueue throws NullPointerException when you try to add null on the queue.
| BlockingQueue<String> bQueue = new ArrayBlockingQueue<String>(10); //bQueue.put(null); //NullPointerException – BlockingQueue in Java doesn’t allow null bQueue = new LinkedBlockingQueue<String>(); bQueue.put(null); Exception in thread “main” java.lang.NullPointerException at java.util.concurrent.LinkedBlockingQueue.put(LinkedBlockingQueue.java:288) |
- BlockingQueue can be bounded or unbounded. A bounded BlockingQueue is one that is initialized with initial capacity and call to put() will be blocked if BlockingQueue is full and size is equal to capacity. This bounding nature makes it ideal to use a shared queue between multiple threads like in most common Producer consumer solutions in Java. An unbounded Queue is one that is initialized without capacity, actually by default it is initialized with Integer.MAX_VALUE. The most common example of BlockingQueue uses bounded BlockingQueue as shown below example.
| BlockingQueue<String> bQueue = new ArrayBlockingQueue<String>(2); bQueue.put(“Java”); System.out.println(“Item 1 inserted into BlockingQueue”); bQueue.put(“JDK”); System.out.println(“Item 2 is inserted on BlockingQueue”); bQueue.put(“J2SE”); System.out.println(“Done”); |
| Output: Item 1 inserted into BlockingQueue Item 2 is inserted on BlockingQueue |
- BlockingQueue implementations like ArrayBlockingQueue, LinkedBlockingQueue, and PriorityBlockingQueue are thread-safe. All queuing method uses concurrency control and internal locks to perform operation atomically. Since BlockingQueue also extends Collection, bulk Collection operations like addAll(), containsAll() are not performed atomically until any BlockingQueue implementation specifically supports it. So call to addAll() may fail after inserting a couple of elements.
- Common methods of BlockingQueue are put() and take() which are blocking methods in Java and used to insert and retrieve elements from BlockingQueue in Java. put() will block if BlockingQueue is full and take() will block if BlockingQueue is empty, call to take() removes an element from the head of Queue
- BlockingQueue interface extends Collection, Queue, and Iterable interface which provides it all Collection and Queue related methods like poll(), and peak(), unlike take(), peek() method returns the head of the queue without removing it, poll() also retrieves and removes elements from the head but can wait till specified time if Queue is empty.
- Other important methods from BlockingQueue in Java is remainingCapacity() and offer(), the former returns the number of remaining space in BlockingQueue, which can be filled without blocking while later inserting an object into the queue if possible and return true if successful and false if fail, unlike add() method which throws IllegalStateException if it fails to insert an object into BlockingQueue. Use offer() over add() wherever possible.
| import java.util.concurrent.BlockingQueue; public class Producer implements Runnable{ BlockingQueue<Object> queue = null; Producer(BlockingQueue<Object> theQueue) { this.queue = theQueue; } @Override public void run() { while (true) { try { Object obj = getResource(); queue.put(obj); System.out.println(“Produced Resource – Queue size now : ” + queue.size()); } catch (InterruptedException e) { e.printStackTrace(); } } } public Object getResource() { try { Thread.sleep(100); } catch (InterruptedException e) { System.out.println(“Thread Interrupted”); } return new Object(); } } import java.util.concurrent.BlockingQueue; public class Consumer implements Runnable{ BlockingQueue<Object> queue = null; public Consumer(BlockingQueue<Object> theQueue) { this.queue = theQueue; } @Override public void run() { try { Object obj = queue.take(); System.out.println(“Consumed Object – Queue size now : ” + queue.size()); take(obj); } catch (InterruptedException e) { e.printStackTrace(); } } public static void take(Object obj) { try { Thread.sleep(100); } catch (InterruptedException e) { System.out.println(“Thread Interrupted”); } System.out.println(“Consumed Resource : ” + obj); } } import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; public class ProducerConsumerExample { public static void main(String[] args) throws InterruptedException { BlockingQueue<Object> queue = new LinkedBlockingQueue<>(20); int numProducer = 4; int numConsumer = 4; for (int i=0; i<numProducer; i++) { new Thread(new Producer(queue)).start();; } for (int j=0; j<numConsumer; j++) { new Thread(new Consumer(queue)).start(); } Thread.sleep(10*100); System.exit(0); } } |
5. Explain Coundownlatch in Java?
CountDownLatch in Java is a kind of synchronizer which allows one Thread to wait for one or more Threads before starts processing.
This is a very crucial requirement and often needed in server-side core Java applications and having this functionality built-in as CountDownLatch greatly simplifies the development.
CountDownLatch in Java is introduced on Java 5 along with other concurrent utilities like CyclicBarrier, Semaphore, ConcurrentHashMap, and BlockingQueue in java.util.concurrent package.
CountDownLatch works in the latch principle, the main thread will wait until Gate is open. One thread waits for n number of threads specified while creating CountDownLatch in Java. Any thread, usually the main thread of the application, which calls CountDownLatch.await() will wait until the count reaches zero or it’s interrupted by another Thread. All other threads are required to do a count down by calling CountDownLatch.countDown() once they are completed or ready for the job. as soon as the count reaches zero, Thread awaiting starts running.
One of the disadvantages of CountDownLatch is that it’s not reusable once the count reaches zero you cannot use CountDownLatch any more, but don’t worry Java concurrency API has another concurrent utility called CyclicBarrier for such requirements.
Example
In this section, we will see a full-featured real-world example of using CountDownLatch in Java. In the following CountDownLatch example, the Java program requires 3 services namely CacheService, AlertService, and ValidationService to be started and ready before the application can handle any request and this is achieved by using CountDownLatch in Java.
| import java.util.Date; import java.util.concurrent.CountDownLatch; import java.util.logging.Level; import java.util.logging.Logger; /** * Java program to demonstrate How to use CountDownLatch in Java. CountDownLatch is * useful if you want to start the main processing thread once its dependency is completed * as illustrated in this CountDownLatch Example * */ public class CountDownLatchDemo { public static void main(String args[]) { final CountDownLatch latch = new CountDownLatch(3); Thread cacheService = new Thread(new Service(“CacheService”, 1000, latch)); Thread alertService = new Thread(new Service(“AlertService”, 1000, latch)); Thread validationService = new Thread(new Service(“ValidationService”, 1000, latch)); cacheService.start(); //separate thread will initialize CacheService alertService.start(); //another thread for AlertService initialization validationService.start(); // application should not start processing any thread until all service is up // and ready to do their job. // Countdown latch is an idle choice here, the main thread will start with count 3 // and wait until the count reaches zero. each thread once up and read will do // a count down. this will ensure that the main thread is not started processing // until all services are up. //count is 3 since we have 3 Threads (Services) try{ latch.await(); //main thread is waiting on CountDownLatch to finish System.out.println(“All services are up, Application is starting now”); } catch(InterruptedException ie){ ie.printStackTrace(); } } } /** * Service class which will be executed by Thread using CountDownLatch synchronizer. */ class Service implements Runnable{ private final String name; private final int timeToStart; private final CountDownLatch latch; public Service(String name, int timeToStart, CountDownLatch latch){ this.name = name; this.timeToStart = timeToStart; this.latch = latch; } @Override public void run() { try { Thread.sleep(timeToStart); } catch (InterruptedException ex) { Logger.getLogger(Service.class.getName()).log(Level.SEVERE, null, ex); } System.out.println( name + ” is Up”); latch.countDown(); //reduce count of CountDownLatch by 1 } } |
| Output: ValidationService is Up AlertService is Up CacheService is Up All services are up, Application is starting now |
By looking at the output of this CountDownLatch example in Java, you can see that the Application is not started until all services started by individual Threads are completed.
6. Explain CyclicBarrier in Java?
CyclicBarrier in Java is a synchronizer introduced in JDK 5 on java.util.Concurrent package along with other concurrent utilities like Counting Semaphore, BlockingQueue, ConcurrentHashMap, etc.
It is a natural requirement for a concurrent program because it can be used to perform the final part of the task once individual tasks are completed and are similar to CountDownLatch which allows multiple threads to wait for each other (barrier) before proceeding.
All threads which wait for each other to reach the barrier are called parties, CyclicBarrier is initialized with a number of parties to wait and threads wait for each other by calling CyclicBarrier.await() method which is a blocking method in Java and blocks until all Thread or parties call await().
In general calling await() is shout out that Thread is waiting on the barrier.
await() is a blocking call but can be timed out or Interrupted by another thread.
If you look at CyclicBarrier, it also does the same thing but it is different you cannot reuse CountDownLatch once the count reaches zero while you can reuse CyclicBarrier by calling reset () method which resets Barrier to its initial State.
What it implies is that CountDownLatch is good for one-time events like application start-up time and CyclicBarrier can be used in case of a recurrent event e.g. concurrently calculating a solution of the big problem etc.
Example
Here is a simple example of CyclicBarrier in Java on which we initialize CyclicBarrier with 3 parties, which means in order to cross the barrier, 3 thread needs to call await() method.
Each thread calls await method for a short duration but they don’t proceed until all 3 threads reached the barrier, once all threads reach the barrier, the barrier gets broker and each thread started their execution from that point.
It’s much clear with the output of following example of CyclicBarrier in Java:
import java.util.concurrent.BrokenBarrierException; import java.util.concurrent.CyclicBarrier; import java.util.logging.Level; import java.util.logging.Logger; /** * Java program to demonstrate how to use CyclicBarrier in Java. CyclicBarrier is a * new Concurrency Utility added in Java 5 Concurrent package. * */ public class CyclicBarrierExample { //Runnable task for each thread private static class Task implements Runnable { private CyclicBarrier barrier; public Task(CyclicBarrier barrier) { this.barrier = barrier; } @Override public void run() { try { System.out.println(Thread.currentThread().getName() + ” is waiting on the barrier”); barrier.await(); System.out.println(Thread.currentThread().getName() + ” has crossed the barrier”); } catch (InterruptedException ex) { Logger.getLogger(CyclicBarrierExample.class.getName()).log(Level.SEVERE, null, ex); } catch (BrokenBarrierException ex) { Logger.getLogger(CyclicBarrierExample.class.getName()).log(Level.SEVERE, null, ex); } } } public static void main(String args[]) { //creating CyclicBarrier with 3 parties i.e. 3 Threads needs to call await() final CyclicBarrier cb = new CyclicBarrier(3, new Runnable(){ @Override public void run(){ //This task will be executed once all thread reaches barrier System.out.println(“All parties are arrived at barrier, lets play”); } }); //starting each of thread Thread t1 = new Thread(new Task(cb), “Thread 1”); Thread t2 = new Thread(new Task(cb), “Thread 2”); Thread t3 = new Thread(new Task(cb), “Thread 3”); t1.start(); t2.start(); t3.start(); } } |
| Output: Thread 1 is waiting on the barrier Thread 3 is waiting on the barrier Thread 2 is waiting on the barrier All parties have arrived at the barrier, lets play Thread 3 has crossed the barrier Thread 1 has crossed the barrier Thread 2 has crossed the barrier |
When to use CyclicBarrier in Java
Given the nature of CyclicBarrier, it can be very handy to implement a map-reduce kind of task similar to the fork-join framework of Java 7, where a big task is broken down into smaller pieces and to complete the task you need output from individual small task
e.g. to count the population of India you can have 4 threads that count the population from North, South, East, and West, and once complete they can wait for each other, When the last thread completed its task, the Main thread or any other thread can add result from each zone and print total population. You can use CyclicBarrier in Java :
- To implement a multi-player game that cannot begin until all player has joined.
- Perform lengthy calculations by breaking them into smaller individual tasks, In general, to implement the Map reduce technique.
The important point of CyclicBarrier in Java
- CyclicBarrier can perform a completion task once all thread reaches the barrier, this can be provided while creating CyclicBarrier.
- If CyclicBarrier is initialized with 3 parties means 3 thread needs to call await method to break the barrier.
- The thread will block on await() until all parties reach the barrier, another thread interrupt or await timed out.
- If another thread interrupts the thread which is waiting on barrier it will throw BrokernBarrierException as shown below:
| java.util.concurrent.BrokenBarrierException at java.util.concurrent.CyclicBarrier.dowait(CyclicBarrier.java:172) at java.util.concurrent.CyclicBarrier.await(CyclicBarrier.java:327) |
CyclicBarrier.reset() put Barrier on its initial state, other thread which is waiting or not yet reached barrier will terminate with java.util.concurrent.BrokenBarrierException.
7. What’s a volatile variable in Java?
The volatile keyword in Java is used as an indicator to Java compiler and Thread that do not cache the value of this variable and always read it from main memory.
So if you want to share any variable in which the read and write operation is atomic by implementation e.g. read and write in an int or a boolean variable then you can declare them as a volatile variable.
The Java volatile keyword cannot be used with method or class and it can only be used with a variable.
Java volatile keyword also guarantees visibility and ordering, after Java 5 writes to any volatile variable happens before any read into the volatile variable. By the way use of volatile keywords also prevents the compiler or JVM from reordering code or moving away from them from the synchronization barrier.
The Volatile variable Example
To Understand the example of a volatile keyword in java let’s go back to the Singleton pattern in Java and see double-checked locking in Singleton with Volatile and without the volatile keyword in java.
| public class Singleton{ private static volatile Singleton _instance; //volatile variable public static Singleton getInstance(){ if(_instance == null){ synchronized(Singleton.class){ if(_instance == null) _instance = new Singleton(); } } return _instance; } |
If you look at the code carefully you will be able to figure out:
- We are only creating instances one time
- We are creating instances lazily at the time the first request comes.
If we do not make the _instance variable volatile then the Thread which is creating an instance of Singleton is not able to communicate other thread, that instance has been created until it comes out of the Singleton block, so if Thread A is creating the Singleton instance and just after creation lost the CPU, all other thread will not be able to see the value of _instance as not null and they will believe it’s still null.
So in Summary apart from synchronized keyword in Java, volatile keyword is also used to communicate the content of memory between threads.
When to use Volatile variables in Java
You can use the Volatile variable if you want to read and write long and double variables atomically. long and double both are 64-bit data types and by default writing of long and double is not atomic and platform dependent. Many platforms perform write in long and double variable 2 step, writing 32 bit in each step, due to this it’s possible for a Thread to see 32 bit from two different writers. You can avoid this issue by making the long and double variables volatile in Java.
A volatile variable can be used as an alternative way of achieving synchronization in Java in some cases, like Visibility. With a volatile variable, it’s guaranteed that all reader threads will see the updated value of the volatile variable once the write operation is completed, without volatile keyword different reader thread may see different values.
It can be used to inform the compiler that a particular field is subject to be accessed by multiple threads, which will prevent the compiler from doing any reordering or any kind of optimization which is not desirable in a multi-threaded environment. Without a volatile variable, the compiler can re-order the code, free to cache the value of the volatile variable instead of always reading from the main memory.
Another place where a volatile variable can be used is to fix double-checked locking in the Singleton pattern. As we discussed in Why should you use Enum as Singleton that double-checked locking was broken in Java 1.4 environment?
8. Difference between synchronized and volatile keywords in Java?
- The volatile keyword in Java is a field modifier while synchronized modifies code blocks and methods.
- Synchronized obtains and releases the lock on the monitor’s Java volatile keyword doesn’t require that.
- Threads in Java can be blocked for waiting for any monitor in case of synchronization, that is not the case with the volatile keyword in Java.
- The synchronized method affects performance more than a volatile keyword in Java.
- Since volatile keyword in Java only synchronizes the value of one variable between thread memory and “main” memory while synchronized synchronizes the value of all variables between thread memory and “main” memory and locks and releases a monitor to boot. Due to this reason, synchronized keyword in Java is likely to have more overhead than volatile ones.
- You cannot synchronize on the null object but your volatile variable in Java could be null.
- From Java 5 writing into a volatile field has the same memory effect as a monitor release, and reading from a volatile field has the same memory effect as a monitor acquire
9. What’s Reentrant Lock in Java?
In Java 5.0, a new addition called Reentrant Lock was made to enhance intrinsic locking capabilities. Prior to this, “synchronized” and “volatile” were the means for achieving concurrency.
| public synchronized void doAtomicTransfer(){ //enter synchronized block , acquire lock over this object. operation1() operation2(); } // exiting synchronized block, release lock over this object. |
Synchronized uses intrinsic locks or monitors. Every object in Java has an intrinsic lock associated with it. Whenever a thread tries to access a synchronized block or method, it acquires the intrinsic lock or the monitor on that object.
In the case of static methods, the thread acquires the lock over the class object. An intrinsic locking mechanism is a clean approach in terms of writing code and is pretty good for most of the use-cases.
An intrinsic locking mechanism can have some functional limitations, such as:
- It is not possible to interrupt a thread waiting to acquire a lock (lock Interruptible).
- It is not possible to attempt to acquire a lock without being willing to wait for it forever (try lock).
- Cannot implement non-block-structured locking disciplines, as intrinsic locks must be released in the same block in which they are acquired.
Lets see a few of the methods implemented by ReentrantLock class (which implements Lock):
| void lock(); void lockInterruptibly() throws InterruptedException; boolean tryLock(); boolean tryLock(long time, TimeUnit unit) throws InterruptedException; ….. |
Let’s try and understand the use of these and see what benefits we can get.
Polled and Timed Lock Acquisition
Let’s see some example code:
| public void transferMoneyWithSync(Account fromAccount, Account toAccount, float amount) throws InsufficientAmountException { synchronized (fromAccount) { // acquired lock on fromAccount Object synchronized (toAccount) { // acquired lock on toAccount Object if (amount > fromAccount.getCurrentAmount()) { throw new InsufficientAmountException( “Insufficient Balance”); } else { fromAccount.debit(amount); toAccount.credit(amount); } } } } |
In the transferMoney() method above, there is a possibility of deadlock when two threads A and B are trying to transfer money at almost the same time.
| A: transferMoney(acc1, acc2, 20); B: transferMoney(acc2, acc1 ,25); |
It is possible that thread A has acquired a lock on the acc1 object and is waiting to acquire a lock on the acc2 object. Meanwhile, thread B has acquired a lock on the acc2 object and is waiting for a lock on acc1. This will lead to deadlock, and the system would have to be restarted! There is, however, a way to avoid this, which is called “lock ordering.” Personally, I find this a bit complex.
A cleaner approach is implemented by ReentrantLock with the use of tryLock() method. This approach is called the “timed and polled lock-acquisition.” It lets you regain control if you cannot acquire all the required locks, release the ones you have acquired, and retry. So, using tryLock, we will attempt to acquire both locks. If we cannot attain both, we will release if one of these has been acquired, then retry.
| public boolean transferMoneyWithTryLock(Account fromAccount, Account toAccount, float amount) throws InsufficientAmountException, InterruptedException { // we are defining a stopTime long stopTime = System.nanoTime() + 5000; while (true) { if (fromAccount.lock.tryLock()) { try { if (toAccount.lock.tryLock()) { try { if (amount > fromAccount.getCurrentAmount()) { throw new InsufficientAmountException( “Insufficient Balance”); } else { fromAccount.debit(amount); toAccount.credit(amount); } } finally { toAccount.lock.unlock(); } } } finally { fromAccount.lock.unlock(); } } if(System.nanoTime() < stopTime) return false; Thread.sleep(100); }//while } |
Here we implemented a timed lock, so if the locks cannot be acquired within the specified time, the transferMoney method will return a failure notice and exit gracefully. We can also maintain time budget activities using this concept.
Interruptible Lock Acquisition
Interruptible lock acquisition allows locking to be used within cancellable activities.
The lockInterruptibly() method allows us to try and acquire a lock while being available for the interruption. So, basically, it allows the thread to immediately react to the interrupt signal sent to it from another thread.
This can be helpful when we want to send a KILL signal to all the waiting locks.
Let’s see one example: Suppose we have a shared line to send messages. We would want to design it in such a way that if another thread comes and interrupts the current thread, the lock should release and perform the exit or shut down operations to cancel the current task.
| public boolean sendOnSharedLine(String message) throws InterruptedException{ lock.lockInterruptibly(); try{ return cancellableSendOnSharedLine(message); } finally { lock.unlock(); } } private boolean cancellableSendOnSharedLine(String message){ ……. |
The timed tryLock is also responsive to interruption.
Non-block Structured Locking:
In intrinsic locks, acquire-release pairs are block-structured.
In other words, a lock is always released in the same basic block in which it was acquired, regardless of how control exits the block.
Extrinsic locks allow the facility to have more explicit control. Some concepts, like Lock Strapping, can be achieved more easily using extrinsic locks. Some use cases are seen in hash-bashed collections and linked lists.
Fairness:
The ReentrantLock constructor offers a choice of two fairness options: create a non-fair lock or a fair lock. With fair locking, threads can acquire locks only in the order in which they were requested, whereas an unfair lock allows a lock to acquire it out of its turn. This is called barging (breaking the queue and acquiring the lock when it became available).
Fair locking has a significant performance cost because of the overhead of suspending and resuming threads. There could be cases where there is a significant delay between when a suspended thread is resumed and when it actually runs. Let’s see a situation:
A -> holds a lock.
B -> has requested and is in a suspended state waiting for A to release the lock.
C -> requests the lock at the same time that A releases the lock, and has not yet gone to a suspended state.
As C has not yet gone to a suspended state, there is a chance that it can acquire the lock released by A, use it, and release it before B even finishes waking up. So, in this context, an unfair lock has a significant performance advantage.
Intrinsic locks and extrinsic locks have the same mechanism inside for locking, so the performance improvement is purely subjective. It depends on the use cases we discussed above. Extrinsic locks give a more explicit control mechanism for better handling of deadlocks, starvation, and so on.
import java.util.concurrent.locks.ReentrantLock; import java.util.logging.Level; import java.util.logging.Logger; /** * Java program to show, how to use ReentrantLock in Java. * Reentrant lock is an alternative way of locking * apart from implicit locking provided by synchronized keyword in Java. */ public class ReentrantLockHowto { private final ReentrantLock lock = new ReentrantLock(); private int count = 0; //Locking using Lock and ReentrantLock public int getCount() { lock.lock(); try { System.out.println(Thread.currentThread().getName() + ” gets Count: ” + count); return count++; } finally { lock.unlock(); } } //Implicit locking using synchronized keyword public synchronized int getCountTwo() { return count++; } public static void main(String args[]) { final ThreadTest counter = new ThreadTest(); Thread t1 = new Thread() { @Override public void run() { while (counter.getCount() < 6) { try { Thread.sleep(100); } catch (InterruptedException ex) { ex.printStackTrace(); } } } }; Thread t2 = new Thread() { @Override public void run() { while (counter.getCount() < 6) { try { Thread.sleep(100); } catch (InterruptedException ex) { ex.printStackTrace(); } } } }; t1.start(); t2.start(); public void run() { while (counter.getCount() < 6) { try { Thread.sleep(100); } catch (InterruptedException ex) { ex.printStackTrace(); } } } }; t1.start(); t2.start(); } } |
| Output: Thread-0 gets Count: 0 Thread-1 gets Count: 1 Thread-1 gets Count: 2 Thread-0 gets Count: 3 Thread-1 gets Count: 4 Thread-0 gets Count: 5 Thread-0 gets Count: 6 Thread-1 gets Count: 7 |
10. Explain Java Inter-thread Communication using Piped Streams?
What are piped streams?
Pipe streams are just like real plumbing pipes. You put things into a pipe at one end using some methods. Then you receive the same things back from the pipe stream at the other end using some other methods. They come out in FIFO order, first-in-first-out, just like from real plumbing pipes.
PipedReader and PipedWriter
PipedReader is an extension of Reader class which is used for reading character streams. Its read() method reads the connected PipedWriter’s stream. Similarly, PipedWriter is an extension of the Writer class and does all the things which Reader class contracts.
A writer can be connected to a reader by following two methods:
- Using constructor PipedWriter(PipedReader pr)
- Using connect(PipedReader pr) method
Once connected through any of the above ways, any thread can write data in a stream using the write(….) methods, and data will be available to the reader and can be read using the read() method.
Example
Below given sample program creates two threads. One thread is responsible for writing into the stream and the second one is only reading the data to print them in the console.
| import java.io.*; public class PipedCommunicationTest { public static void main(String[] args) { new PipedCommunicationTest(); } public PipedCommunicationTest() { try { // Create writer and reader instances PipedReader pr = new PipedReader(); PipedWriter pw = new PipedWriter(); // Connect the writer with reader pw.connect(pr); // Create one writer thread and one reader thread Thread thread1 = new Thread( new PipeReaderThread(“ReaderThread”, pr)); Thread thread2 = new Thread( new PipeWriterThread(“WriterThread”, pw)); // start both threads thread1.start(); thread2.start(); } catch (Exception e) { System.out.println(“PipeThread Exception: ” + e); } } } class PipeReaderThread implements Runnable { PipedReader pr; String name = null; public PipeReaderThread(String name, PipedReader pr) { this.name = name; this.pr = pr; } public void run() { try { // continuously read data from stream and print it in console while (true) { char c = (char) pr.read(); // read a char if (c != -1) { // check for -1 indicating end of file System.out.print(c); } } } catch (Exception e) { System.out.println(” PipeThread Exception: ” + e); } } } class PipeWriterThread implements Runnable { PipedWriter pw; String name = null; public PipeWriterThread(String name, PipedWriter pw) { this.name = name; this.pw = pw; } public void run() { try { while (true) { // Write some data after every two seconds pw.write(“Testing data are written…n”); pw.flush(); Thread.sleep(2000); } } catch (Exception e) { System.out.println(” PipeThread Exception: ” + e); } } } |
| Output: Testing data are written… Testing data are written… Testing data are written… |
Important notes
- You cannot write to a pipe without having some sort of reader created and connected to it. In other words, both ends must be present and already connected for the writing end to work.
- You cannot switch to another reader, to which the pipe was not originally connected, once you are done writing to a pipe.
- You cannot read back from the pipe if you close the reader. You can close the writing end successfully, however, and still read from the pipe.
You cannot read back from the pipe if the thread which wrote to it ends.
11. Explain Java ThreadLocal Variables?
Today, one of the most critical aspects of a concurrent application is shared data. When you create a thread that implements the Runnable interface and then start various Thread objects using the same Runnable object, all the threads share the same attributes that are defined inside the runnable object.
This essentially means that if you change any attribute in a thread, all the threads will be affected by this change and will see the modified value by the first thread.
Sometimes it is desired behavior e.g. multiple threads increasing/decreasing the same counter variable, but sometimes you want to ensure that every thread MUST work on its own copy of the thread instance and does not affect others data.
When to use ThreadLocal?
For example, consider you are working on an eCommerce application. You have a requirement to generate a unique transaction id for each and every customer request this controller process and you need to pass this transaction id to the business methods in manager/DAO classes for logging purposes. One solution could be passing this transaction id as a parameter to all the business methods. But this is not a good solution as the code is redundant and unnecessary.
To solve that, here you can use the ThreadLocal variable. You can generate a transaction id in the controller OR any pre-processor interceptor; and set this transaction id in the ThreadLocal. After this, whatever the methods, that this controller calls, they all can access this transaction id from the threadlocal. Also note that the application controller will be servicing more than one request at a time and since each request is processed in a separate thread at the framework level, the transaction id will be unique to each thread and will be accessible from all over the thread’s execution path.
Inside ThreadLocal Class?
The Java Concurrency API provides a clean mechanism for thread-local variables using ThreadLocal class with a very good performance.
public class ThreadLocal<T> extends Object {…}
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its get or set method) has its own, independently initialized copy of the variable. ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID).
This class has the following methods:
- get() : Returns the value in the current thread’s copy of this thread-local variable.
- initialValue() : Returns the current thread’s “initial value” for this thread-local variable.
- remove() : Removes the current thread’s value for this thread-local variable.
- set(T value) : Sets the current thread’s copy of this thread-local variable to the specified value.
How to use ThreadLocal?
The below example uses two thread-local variables i.e. threadId and startDate. Both have been defined as “private static” fields as recommended. ‘threadId‘ will be used to identify the thread which is currently running and ‘startDate‘ will be used to get the time when the thread started its execution. The above information will be printed in the console to verify that each thread has maintained its own copy of variables.
| class DemoTask implements Runnable { // Atomic integer containing the next thread ID to be assigned private static final AtomicInteger nextId = new AtomicInteger(0); // Thread local variable containing each thread’s ID private static final ThreadLocal<Integer> threadId = new ThreadLocal<Integer>() { @Override protected Integer initialValue() { return nextId.getAndIncrement(); } }; // Returns the current thread’s unique ID, assigning it if necessary public int getThreadId() { return threadId.get(); } // Returns the current thread’s starting timestamp private static final ThreadLocal<Date> startDate = new ThreadLocal<Date>() { protected Date initialValue() { return new Date(); } }; @Override public void run() { System.out.printf(“Starting Thread: %s : %s\n”, getThreadId(), startDate.get()); try { TimeUnit.SECONDS.sleep((int) Math.rint(Math.random() * 10)); } catch (InterruptedException e) { e.printStackTrace(); } System.out.printf(“Thread Finished: %s : %s\n”, getThreadId(), startDate.get()); } } |
Now to verify that variables essentially are able to maintain their state irrespective of multiple initializations for multiple threads, let’s create three instances of this task; start the threads; and then verify the information they print in the console.
| Starting Thread: 0 : Wed Dec 24 15:04:40 IST 2014 Thread Finished: 0 : Wed Dec 24 15:04:40 IST 2014 Starting Thread: 1 : Wed Dec 24 15:04:42 IST 2014 Thread Finished: 1 : Wed Dec 24 15:04:42 IST 2014 Starting Thread: 2 : Wed Dec 24 15:04:44 IST 2014 Thread Finished: 2 : Wed Dec 24 15:04:44 IST 2014 |
In the above output, the sequence of the printed statements will vary every time. I have put them in sequence so that we can clearly identify that thread-local values are kept safe for each thread instance; never intermixed.
The most common use of thread-local is when you have some object that is not thread-safe, but you want to avoid synchronizing access to that object using a synchronized keyword/block. Instead, give each thread its own instance of the object to work with.
A good alternative to synchronization or threadlocal is to make the variable a local variable. Local variables are always thread-safe. The only thing which may prevent you to do this is your application design constraints.
12. Object-level Locking vs. Class level Locking in Java
- Synchronization refers to multi-threading. A synchronized block of code can only be executed by one thread at a time.
- Java supports multiple threads to be executed. This may cause two or more threads to access the same fields or objects.
- Synchronization is a process that keeps all concurrent thread’s execution to be in synch.
- Synchronization avoids memory consistency errors caused due to inconsistent views of shared memory.
- When a method is declared as synchronized; the thread holds the monitor for that method’s object, if another thread is executing the synchronized method, your thread is blocked until that thread releases the monitor.
- Synchronization in java is achieved using the synchronized keyword. You can use synchronized keywords in your class on defined methods or blocks. Keywords cannot be used with variables or attributes in the class definition.
Object-level locking
- Object-level locking is a mechanism when you want to synchronize a non-static method or non-static code block such that only one thread will be able to execute the code block on a given instance of the class.
- This should always be done to make instance-level data thread-safe. This can be done as below:
| public class DemoClass { public synchronized void demoMethod(){} } or public class DemoClass { public void demoMethod(){ synchronized (this) { //other thread-safe code } } } or public class DemoClass { private final Object lock = new Object(); public void demoMethod(){ synchronized (lock) { //other thread-safe code } } } |
Class level locking
- Class level locking prevents multiple threads to enter a synchronized block in any of all available instances on runtime.
- This means if in runtime there are 100 instances of DemoClass, then only one thread will be able to execute demoMethod() in any one of instance at a time, and all other instances will be locked for other threads. This should always be done to make static data thread-safe.
| public class DemoClass { public synchronized static void demoMethod(){} } or public class DemoClass { public void demoMethod(){ synchronized (DemoClass.class) { //other thread-safe code } } } or public class DemoClass { private final static Object lock = new Object(); public void demoMethod(){ synchronized (lock) { //other thread-safe code } } } |
Some Important Points
- Synchronization in Java guarantees that no two threads can execute a synchronized method that requires the same lock simultaneously or concurrently.
- The synchronized keyword can be used only with methods and code blocks. These methods or blocks can be static or non-static.
- Whenever a thread enters into the java synchronized method or block it acquires a lock and whenever it leaves the java synchronized method or block it releases the lock. The lock is released even if the thread leaves the synchronized method after completion or due to any Error or Exception.
- java synchronized keyword is re-entrant in nature which means if a java synchronized method calls another synchronized method that requires the same lock then the current thread which is holding the lock can enter into that method without acquiring the lock.
- Java Synchronization will throw NullPointerException if the object used in the java synchronized block is null. For example, in the above code sample, if the lock is initialized as null, the synchronized (lock) will throw NullPointerException.
- Synchronized methods in Java put a performance cost on your application. So use synchronization when it is absolutely required. Also, consider using synchronized code blocks for synchronizing only the critical sections of your code.
- It’s possible that both static synchronized and non-static synchronized methods can run simultaneously or concurrently because they lock on a different object.
- According to the Java language specification you cannot use java synchronized keyword with constructor it’s illegal and results in a compilation error.
- Do not synchronize the non-final field on the synchronized block in Java. Because reference of the non-final field may change at any time and then different threads might synchronize on different objects i.e. no synchronization at all. The best is to use the String class, which is already immutable and declared final.
13. Can we make an Array or ArrayList as volatile in Java?
volatile modifier
- The volatile is a modifier in Java that only applies to member variables, both instance, and class variables, and both primitive and reference types. It provides the happens-before guarantee which ensures that a write to a volatile variable will happen before any reading. This ensures that any modification to a volatile object or primitive type will be visible to all threads i.e. it provides the visibility guarantee.
- The volatile modifier also provides an ordering guarantee because the compiler cannot re-order any code or operation which involves volatile variables (primitive and objects), but what is perhaps more important to know and remember is that volatile variable doesn’t provide atomicity (except for write to the volatile double variable) and mutual exclusion, which is also the main difference between volatile and synchronized keyword.
- There are certain restrictions with volatile keywords e.g. you cannot make a member variable both final and volatile at the same time, but you can make a static variable volatile in Java.
Can we make the array volatile in Java?
- The answer is, Yes, you can make an array (both primitive and reference type array e.g. an int array and String array) volatile in Java but only changes to reference pointing to an array will be visible to all threads, not the whole array. What this means is that suppose you have a reference variable called primes as shown below:
protected volatile int[] primes = new int[10];
- then if you assign a new array to primes variable, change will be visible to all threads, but changes to individual indices will not be covered under volatile guarantee i.e.
primes = new int[20];
- will follow the “happens-before” rule and cause memory barrier refresh, but following code will not do so
primes[0] = 10;
primes[1] = 20;
primes[2] = 30;
primes[3] = 40;
- This means, that if multiple threads are changing individual array elements e.g. storing updates, there won’t be any happens-before guarantee provided by the volatile modifier for such modification. So, if your use case is to provide a memory visibility guarantee for individual array elements then volatile is not the right choice. You must rely on other synchronization and a thread-safety mechanism to cover this case e.g. synchronized keyword, atomic variables, or ReentrantLock.
Can we make ArrayList or HashMap volatile in Java?
- The answer is the same, of course, you can make a reference variable pointing to a Collection volatile in Java, but the happens-before guarantee will only be provided if the value of that reference variable is changed e.g. you assign a new collection to it.
- Any modification done on the actual collection object e.g. adding or removing elements from ArrayList will not invoke the happens-before guarantee or memory barrier refresh.
14. Why wait(), notify() and notifyAll() must be called from a synchronized block or method in Java?
- We use wait(), notify(), or notifyAll() method mostly for inter-thread communication in Java. One thread is waiting after checking a condition
- e.g. In the classic Producer-Consumer problem, the Producer thread waits if the buffer is full and the Consumer thread notifies the Producer thread after it creates a space in the buffer by consuming an element.
- Calling notify() or notifyAll() methods issues a notification to a single or multiple threads that a condition has changed and once the notification thread leaves the synchronized block, all the threads which are waiting for a fight for the object lock on which they are waiting and lucky thread returns from wait() method after reacquiring the lock and proceed further.
- Let’s divide this whole operation into steps to see the possibility of race conditions between wait() and notify() method in Java, we will use the Produce Consumer thread example to understand the scenario better:
- The Producer thread tests the condition (buffer is full or not) and confirms that it must wait (after finding the buffer is full).
- The Consumer thread sets the condition after consuming an element from a buffer.
- The Consumer thread calls the notify () method; this goes unheard since the Producer thread is not yet waiting.
- The Producer thread calls the wait () method and goes into a waiting state.
- So due to race conditions here we potentially lost a notification and if we use buffer or just one element Produce thread will be waiting forever and your program will hang.
- This race condition is resolved by using synchronized keywords and locking provided by Java. In order to call the wait (), notify (), or notifyAll () methods in Java, we must have obtained the lock for the object on which we’re calling the method.
- Since the wait() method in Java also releases the lock prior to waiting and reacquires the lock prior to returning from the wait() method, we must use this lock to ensure that checking the condition (buffer is full or not) and setting the condition (taking element from the buffer) is atomic which can be achieved by using synchronized method or block in Java.
Summary
- IllegalMonitorStateException in Java will occur if we don’t call wait (), notify (), or notifyAll () method from a synchronized context.
- Any potential race condition between the wait and notify method in Java.
15. How to Implement your own Thread pool in java?
- Thread Pool is a pool of threads that reuses a fixed number of threads to execute tasks.
- At any point, most nThreads threads will be active processing tasks. If additional tasks are submitted when all threads are active, they will wait in the queue until a thread is available.
- ThreadPool implementation internally uses LinkedBlockingQueue for adding and removing tasks.
Advantage of ThreadPool?
- Instead of creating a new thread every time for executing tasks, we can create ThreadPool which reuses a fixed number of threads for executing tasks.
- As threads are reused, the performance of our application improves drastically.
Life cycle of threads in ThreadPool
| new ThreadPoolsThread(taskQueue,this); |
- When threads are created in the constructor of ThreadPool they are in a New state.
| threadPoolsThread.start(); |
- When threads are started in the constructor of ThreadPool they enter the Runnable state.
class ThreadPoolsThread extends Thread { . . . public void run() { . . . } . . . } |
- When threads enter run() method of ThreadPoolsThread class they enter the Running state.
- Thread can go from running to waiting for the state when taskQueue.take() is called and taskQueue’s size is 0. The thread will wait for tasks to become available.
- How can tasks become available/ Threads could go from waiting to a runnable state?
- When execute() method of ThreadPool is called, it internally calls put() method on taskQueue to add tasks.
- Once a task is an available thread can go from waiting to a runnable state. And later thread scheduler puts the thread from runnable to running state at the discretion of the implementation.
- Once the shutdown of ThreadPool is initiated, previously submitted tasks are executed by threads and then threads enter a dead state.
How ThreadPool work?
| ThreadPool threadPool=new ThreadPool(2); |
- We will instantiate ThreadPool, in ThreadPool’s constructor nThreads number of threads are created and started.
- Here 2 threads will be created and started in ThreadPool.
- Then, threads will enter run() method of ThreadPoolsThread class and will call take() method on taskQueue.
- If tasks are available thread will execute the task by entering run() method of task (As tasks are executed always implement Runnable). Else waits for tasks to become available.
public void run() { . . . while (true) { . . . Runnable runnable = taskQueue.take(); runnable.run(); . . . } . . . } |
- When tasks are added?
- When execute() method of ThreadPool is called, it internally calls put() method on taskQueue to add tasks.
| taskQueue.put(task); |
- Once tasks are available all waiting threads are notified that the task is available.
- How threads in ThreadPool can be stopped?
- shutDown() method can be used to stop threads executing in threadPool, once the shutdown of ThreadPool is initiated, previously submitted tasks are executed, but no new tasks could be accepted.
- After the thread has been executed task
- Check whether pool shutDown has been initiated or not if pool shutDown has been initiated and
- taskQueue does not contain any unExecuted task (i.e. taskQueue’s size is 0 ) than interrupt() the thread.
public void run() { . . . while (true) { . . . runnable.run(); //task EXECUTED . . . if(this.threadPool.isPoolShutDownInitiated() && this.taskQueue.size()==0) this.interrupt(); } . . . } |
Program to implement ThreadPool in java
| package ThreadPool; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; /** * ThreadPool is a class that creates a thread pool that reuses a fixed * number of threads to execute tasks. * At any point, at most nThreads threads will be active processing tasks. * If additional tasks are submitted when all threads are active, * they will wait in the queue until a thread is available. * * Once shutdown of ThreadPool is initiated, previously submitted tasks are * executed, but no new tasks will be accepted. * */ class ThreadPool { private BlockingQueue<Runnable> taskQueue; /* * Once pool shutDown will be initiated, poolShutDownInitiated will become true. */ private boolean poolShutDownInitiated = false; /* Constructor of ThreadPool * nThreads= is a number of threads that exist in ThreadPool. * nThreads number of threads are created and started. * */ public ThreadPool(int nThreads){ taskQueue = new LinkedBlockingQueue<Runnable>(nThreads); //Create and start nThreads number of threads. for(int i=1; i<=nThreads; i++){ ThreadPoolsThread threadPoolsThread=new ThreadPoolsThread(taskQueue,this); threadPoolsThread.setName(“Thread-“+i); System.out.println(“Thread-“+i +” created in ThreadPool.”); threadPoolsThread.start(); //start thread } } /** * Execute the task, the task must be of Runnable type. */ public synchronized void execute(Runnable task) throws Exception{ if(this.poolShutDownInitiated) throw new Exception(“ThreadPool has been shutDown, no further tasks can be added”); /* * Add task in sharedQueue, * and notify all waiting threads that the task is available. */ System.out.println(“task has been added.”); this.taskQueue.put(task); } public boolean isPoolShutDownInitiated() { return poolShutDownInitiated; } /** * Initiates shutdown of ThreadPool, previously submitted tasks * are executed, but no new tasks will be accepted. */ public synchronized void shutdown(){ this.poolShutDownInitiated = true; System.out.println(“ThreadPool SHUTDOWN initiated.”); } } /** * These threads are created and started from the constructor of ThreadPool class. */ class ThreadPoolsThread extends Thread { private BlockingQueue<Runnable> taskQueue; private ThreadPool threadPool; public ThreadPoolsThread(BlockingQueue<Runnable> queue, ThreadPool threadPool){ taskQueue = queue; this.threadPool=threadPool; } public void run() { try { /* * ThreadPool’s threads will keep on running * until ThreadPool is not shutDown (shutDown will interrupt the thread) and * taskQueue contains some unExecuted tasks. */ while (true) { System.out.println(Thread.currentThread().getName() +” is READY to execute task.”); /*ThreadPool’s thread will take() task from sharedQueue * only if tasks are available else * waits for tasks to become available. */ Runnable runnable = taskQueue.take(); System.out.println(Thread.currentThread().getName() +” has taken task.”); //Now, execute task with current thread. runnable.run(); System.out.println(Thread.currentThread().getName() +” has EXECUTED task.”); /* * 1) Check whether pool shutDown has been initiated or not, * if pool shutDown has been initiated and * 2) taskQueue does not contain any * unExecuted task (i.e. taskQueue’s size is 0 ) * than interrupt() the thread. */ if(this.threadPool.isPoolShutDownInitiated() && this.taskQueue.size()==0){ this.interrupt(); /* * Interrupting basically sends a message to the thread * indicating it has been interrupted but it doesn’t cause * a thread to stop immediately, * * if sleep is called, the thread immediately throws InterruptedException */ Thread.sleep(1); } } } catch (InterruptedException e) { System.out.println(Thread.currentThread().getName()+” has been STOPPED.”); } } } /** * Task class which implements Runnable. */ class Task implements Runnable{ @Override public void run() { try { Thread.sleep(2000); System.out.println(Thread.currentThread().getName() +” is executing task.”); } catch (InterruptedException e) { e.printStackTrace(); } } }; /** * Test ThreadPool. */ public class ThreadPoolTest{ public static void main(String[] args) throws Exception { ThreadPool threadPool=new ThreadPool(2); //create 2 threads in ThreadPool Runnable task=new Task(); threadPool.execute(task); threadPool.execute(task); threadPool.shutdown(); } } |
| OUTPUT Thread-1 created in ThreadPool. Thread-2 created in ThreadPool. Thread-1 is READY to execute task. Thread-2 is READY to execute task. task has been added. task has been added. Thread-1 has taken task. Thread-2 has taken task. ThreadPool SHUTDOWN initiated. Thread-1 is executing task. Thread-1 has EXECUTED task. Thread-1 has been STOPPED. Thread-2 is executing task. Thread-2 has EXECUTED task. Thread-2 has been STOPPED. |
Let’s discuss output in detail, to get a better understanding of the ThreadPool program
- Note: I have mentioned output in green text.
- The total number of threads created in ThreadPool was 2.
Thread-1 was created in ThreadPool.
- Till now Thread-1 has been created.
Thread-2 was created in ThreadPool.
- Till now Thread-2 has been created.
Thread-1 is READY to execute the task.
- Thread-1 has entered run() method and taskQueue’s size is 0. So it’s waiting for the task to become available.
Thread-2 is READY to execute the task.
- Thread-2 has entered run() method and taskQueue’s size is 0. So it is waiting for the task to become available.
the task has been added.
- execute() method of ThreadPool is called by the main thread, it internally calls put() method on taskQueue to add tasks. Once tasks are available all waiting threads are notified that the task is available.
the task has been added.
- execute() method of ThreadPool is called by the main thread, it internally calls put() method on taskQueue to add tasks. Once tasks are available all waiting threads are notified that the task is available.
Thread-1 has taken task.
- As waiting Thread-1 has been notified it takes a task.
Thread-2 has taken task.
- As waiting for Thread-2 has been notified it takes a task.
ThreadPool SHUTDOWN initiated.
- threadPool.shutdown() is called by the main thread, previously submitted tasks are executed, but no new tasks will be accepted.
Thread 1 is executing the task.
- It is in run() method of Task class (shutdown was initiated, but previously submitted tasks are executed ).
Thread-1 has EXECUTED task.
It has been STOPPED.
Thread-2 is executing the task.
- It’s in run() method of the Task class.
Thread-2 has EXECUTED task.
Thread-2 has been STOPPED.
How the performance of applications is improved by reusing threads?
- So, after the constructor and before shutdown is called on ThreadPool, threads will remain either in Running, Runnable, or Waiting state. Therefore excluding the overhead of being in a New and Dead state.
- Therefore, for every task executed by a thread, it would never go into a new and dead state hence saving time and will improve application performance.